Redis는 데이터 구조 서버입니다. Redis는 캐싱에서 큐, 이벤트 처리에 이르기까지 다양한 문제를 해결하는 데 도움이 되는 기본 데이터 유형을 핵심으로 제공합니다. 이 글에서는 데이터 유형에 대한 간략하게 설명합니다.

Table Of Contents
Redis에서 지원하는 데이터 타입
레디스에서 지원하는 데이터 타입은 아래와 같이 매우 다양합니다. 이 글에서는 대표적인 몇 가지 데이터 타입에 대해서 알아보겠습니다.
영어로 된 원문은 아래 링크에서 확인하실 수 있습니다. 이 글에서 각 데이터 타입에 대해서 한글로 자세히 설명드리나, 원문이 필요하신 분은 아래 링크를 확인하시면 됩니다.
Understand Redis data types | Redis
String(문자열)
Redis 문자열 소개
Redis 문자열은 가장 기본적인 Redis 데이터 유형으로, 바이트 시퀀스를 나타냅니다.
Redis 문자열은 텍스트, 직렬화된 객체, 바이너리 배열을 포함한 바이트 시퀀스를 저장합니다. 따라서 문자열은 Redis 키에 연결할 수 있는 가장 간단한 유형의 값입니다. 문자열은 캐싱에 자주 사용되지만 카운터를 구현하고 비트 단위 연산을 수행할 수 있는 추가 기능도 지원합니다.
Redis 키는 문자열이므로 문자열 유형을 값으로도 사용하면 문자열을 다른 문자열에 매핑하는 것입니다. 문자열 데이터 유형은 HTML 조각이나 페이지 캐싱과 같은 여러 사용 사례에 유용합니다.
Redis 문자열 테스트 예제
아래와 같이 redis-cli를 통해서 간단하게 테스트 해 볼 수 있습니다.
> SET bike:1 Deimos
OK
> GET bike:1
"Deimos"
동일한 작업을 하는 것을 파이썬(python)으로 작성하면 다음과 같이 작성할 수 있습니다.
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
res1 = r.set("bike:1", "Deimos")
print(res1) # True
res2 = r.get("bike:1")
print(res2) # Deimos
r.set("total_crashes", 0)
res7 = r.incr("total_crashes")
print(res7) # 1
res8 = r.incrby("total_crashes", 10)
print(res8) # 11
res5 = r.mset({"bike:1": "Deimos", "bike:2": "Ares", "bike:3": "Vanth"})
print(res5) # True
res6 = r.mget(["bike:1", "bike:2", "bike:3"])
print(res6) # ['Deimos', 'Ares', 'Vanth']
위의 예제에서 SET과 GET 명령은 문자열 값을 설정하고 검색하는 방식입니다. 키가 문자열이 아닌 값과 연결되어 있더라도 키에 이미 저장된 기존 값이 있는 경우 SET은 그 값을 대체한다는 점을 유의하시는 것이 좋습니다. 따라서 SET은 할당을 수행합니다.
값은 모든 종류의 문자열(바이너리 데이터 포함)이 될 수 있으며, 예를 들어 값 안에 jpeg 이미지를 저장할 수 있습니다. 값은 512MB보다 클 수 없습니다.
SET 명령에는 추가 인자로 제공되는 흥미로운 옵션이 있습니다. 예를 들어, 키가 이미 존재하는 경우 SET 명령이 실패하도록 하거나 반대로 키가 이미 존재하는 경우에만 성공하도록 요청할 수 있습니다.
문자열을 조작하는 다른 명령은 여러 가지가 있습니다. 예를 들어 GETSET 명령은 키를 새 값으로 설정하고 이전 값을 결과로 반환합니다. 예를 들어 웹 사이트에 새 방문자가 들어올 때마다 INCR을 사용하여 Redis 키를 증가시키는 시스템이 있는 경우 이 명령을 사용할 수 있습니다. 이 정보를 한 시간마다 한 번씩, 한 번의 증분도 잃지 않고 수집하고 싶을 수 있습니다. 키에 새 값 "0"을 할당하고 이전 값을 다시 읽어오는 GETSET을 사용하면 됩니다.
하나의 명령으로 여러 키의 값을 설정하거나 검색하는 기능도 지연 시간을 줄이는 데 유용합니다. 이러한 이유로 MSET 및 MGET 명령이 있습니다.
String에 대한 더 자세한 사항은 아래 링크를 참고하시면 됩니다.
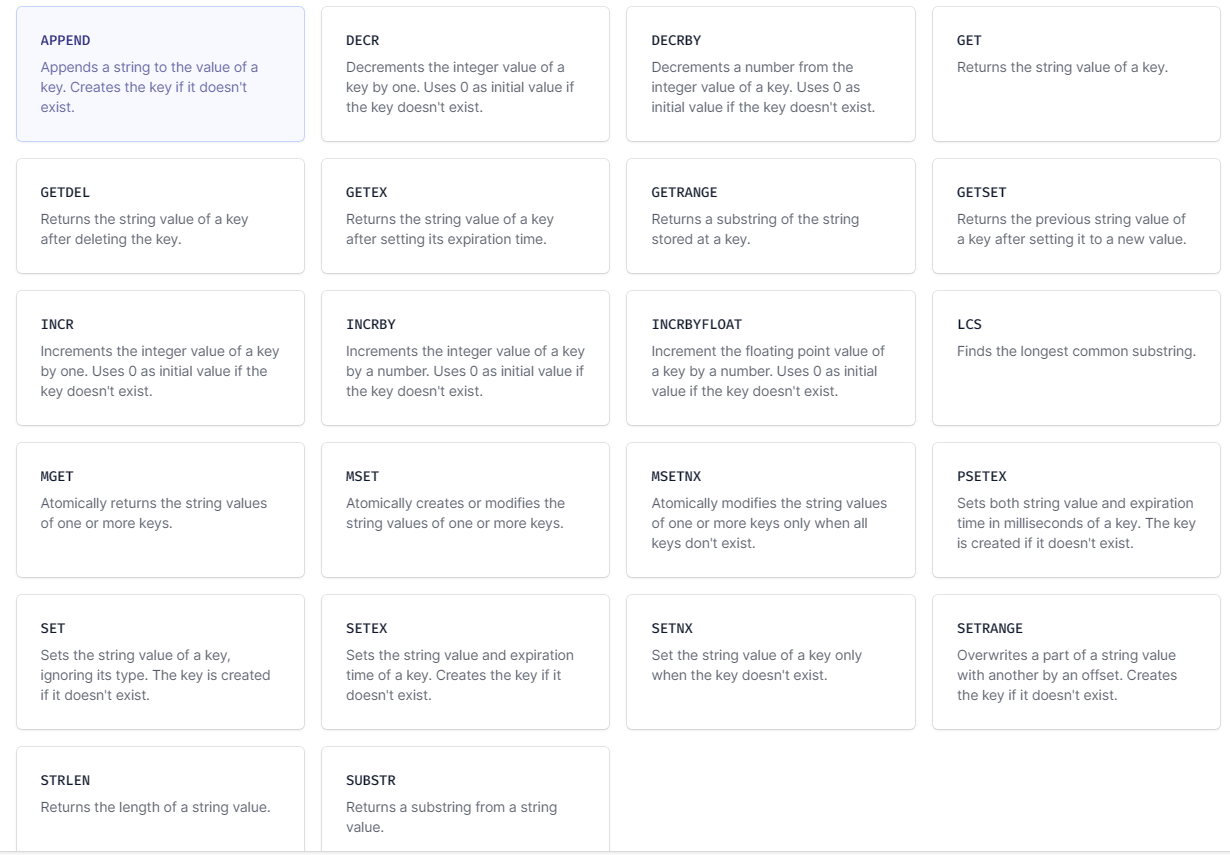
추가로 redis string에서 사용할 수 있는 명령은 아래 사진과 같습니다.
Redis Lists
Redis List는 삽입 순서에 따라 정렬된 문자열 List입니다.
Redis List는 문자열 값의 링크된 목록입니다. Redis List는 많이 사용됩니다.
리스트는 스택과 큐를 구현합니다.
백그라운드 워커 시스템을 위한 큐 관리 구축에 유용합니다.
기본 명령
- LPUSH는 리스트의 앞부분에 새 엘리먼트를 추가하고, RPUSH는 리스트의 뒷부분에 추가합니다. key가 리스트의 이름이자 key이며 element는 value(값)에 해당합니다.
LPUSH key element [element ...]
- LPOP는 리스트의 헤드(head)에서 엘리먼트를 제거하여 반환하고, RPOP는 리스트의 끝(tail)에서 동일한 작업을 수행합니다.
- LLEN은 리스트의 길이를 반환합니다.
- LMOVE는 한 리스트에서 다른 리스트로 엘리먼트를 한번에 이동합니다.
- LTRIM은 리스트를 지정된 범위의 엘리먼트로 줄입니다.
Blocking 명령어
리스트는 여러 가지 블로킹(blocking, 차단) 명령을 지원합니다. 예를 들면 다음과 같습니다:
● BLPOP은 목록의 리스트의 헤드에서 엘리먼트를 제거하고 반환합니다. 리스트가 비어 있는 경우, 이 명령은 엘리먼트를 사용할 수 있게 되거나 지정된 시간 제한에 도달할 때까지 블록(차단)됩니다.
● BLMOVE는 소스 리스트에서 대상 리스트로 엘리먼트들을 한 번에(atomic) 이동합니다. 소스 리스트가 비어 있으면 새 엘리먼트를 사용할 수 있게 될 때까지 명령이 블록(차단)됩니다.
리스트 명령에 대한 전체 내역은 아래 링크를 눌러서 확인하실 수 있습니다.
List 예제
아래에 리스트(list)를 다루는 레디스 명령어들 예제와 각 예제에 대한 설명을 기술합니다.
127.0.0.1:6379> LPUSH mylist "world"
(integer) 1
127.0.0.1:6379> LPUSH mylist "hello"
(integer) 2
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
2) "world"
127.0.0.1:6379> RPOP mylist
"world"
127.0.0.1:6379> LLEN mylist
(integer) 1
127.0.0.1:6379> LRANGE mylist
(error) ERR wrong number of arguments for 'lrange' command
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
127.0.0.1:6379> LPUSH mylist "test1" "test2"
(integer) 3
127.0.0.1:6379> LRANGE mylist 0 -1
1) "test2"
2) "test1"
3) "hello"
127.0.0.1:6379> LPOP mylist
"test2"
127.0.0.1:6379> LRANGE mylist 0 -1
1) "test1"
2) "hello"
127.0.0.1:6379> LTRIM mylist
(error) ERR wrong number of arguments for 'ltrim' command
127.0.0.1:6379> LTRIM mylist 0 0
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "test1"
127.0.0.1:6379>
- LPUSH mylist "world": "mylist"라는 이름의 리스트의 헤드에 "world" 값을 추가합니다. LPUSH 명령어는 리스트의 가장 앞쪽에 값을 추가합니다. 이때, LPUSH 명령어는 추가된 엘리먼트의 개수를 반환합니다.
- LPUSH mylist "hello": "mylist" 리스트의 헤드에 "hello" 값을 추가합니다. LPUSH 명령어는 이미 존재하는 리스트에 엘리먼트를 추가할 때도 사용됩니다.
- LRANGE mylist 0 -1: "mylist" 리스트의 모든 엘리먼트를 반환합니다. 여기서 0과 -1은 시작과 끝을 나타내며, -1은 마지막 엘리먼트를 의미합니다.
- RPOP mylist: "mylist" 리스트의 오른쪽에서 엘리먼트를 제거하고 반환합니다. 이 경우 "world"가 반환됩니다.
- LLEN mylist: "mylist" 리스트의 길이를 반환합니다.
- LRANGE mylist 0 -1: "mylist" 리스트의 모든 엘리먼트를 반환합니다. RPOP을 통해 "world"가 제거되어 현재는 "hello" 하나만 남아 있습니다.
- LPUSH mylist "test1" "test2": "mylist" 리스트의 헤드에 "test1"과 "test2" 값을 동시에 추가합니다.
- LRANGE mylist 0 -1: "mylist" 리스트의 모든 엘리먼트를 반환합니다. 이제는 "test2", "test1", "hello"의 순서로 엘리먼트가 들어 있습니다.
- LPOP mylist: "mylist" 리스트의 헤드에서 엘리먼트를 제거하고 반환합니다. 이 경우 "test2"가 반환됩니다.
- LRANGE mylist 0 -1: "mylist" 리스트의 모든 엘리먼트를 반환합니다. 이제는 "test1"과 "hello"만 남아 있습니다.
- LTRIM mylist 0 0: "mylist" 리스트를 잘라내어 (trim) 첫 번째 엘리먼트인 "test1"만 남기고 나머지는 제거합니다. 이 명령어는 리스트를 시작과 끝 인덱스만 남기고 나머지는 제거하는데 사용됩니다.
리스트에 대한 이해
레디스의 리스트 데이터 유형을 이해하기 위해서는 약간의 이론을 이해해야 합니다. 리스트라는 용어는 IT 기술 종사자들이 부적절한 방식으로 사용하는 경우가 많기 때문입니다. 예를 들어 '파이썬 리스트'는 링크된 리스트가 아니라 배열입니다(실제로 같은 데이터 유형을 루비에서는 배열이라고 부릅니다).
일반적인 관점에서 보면 리스트는 정렬된 요소의 시퀀스일 뿐입니다: 10,20,1,2,3은 리스트입니다. 그러나 배열을 사용하여 구현된 리스트와 Linked List를 사용하여 구현된 리스트의 속성은 서로 매우 다릅니다.
레디스의 리스트는 Linked List를 통해 구현됩니다. 즉, 리스트안에 수백만 개의 요소가 있더라도 리스트의 헤드(head) 또는 끝(Tail)에 새 요소를 추가하는 작업은 일정한 상수 시간에 수행됩니다. 10개의 요소가 있는 목록의 헤드에 LPUSH 명령으로 새 엘리먼트를 추가하는 속도는 천만 개의 엘리먼트가 있는 목록의 헤드에 엘리먼트를 추가하는 속도와 동일합니다.
단점은 무엇일까요? 인덱스로 엘리먼트에 액세스하는 것은 배열로 구현된 리스트(상수 시간 인덱스 액세스)에서는 매우 빠르지만 Linked List(액세스하는 엘리먼트의 인덱스에 비례하여 이동)로 구현된 리스트에서는 그렇게 빠르지 않습니다.
데이터베이스 시스템에서는 매우 긴 리스트에 매우 빠른 방식으로 요소를 추가하는 것이 중요하기 때문에 Redis 리스트는 Linked List로 구현됩니다.
만약 대용량의 엘리먼트를 가진 집합의 중간에 빠르게 액세스하는 것이 중요한 경우 Sorted sets라는 다른 데이터 구조를 사용할 수 있습니다. Sorted sets는 다음 단락에서 설명드립니다.
제한된 목록(capped lists)
많은 사용 사례에서 우리는 소셜 네트워크 업데이트, 로그 등 무엇이든 최신 항목을 저장하기 위해 리스트를 사용하고자 합니다.
Redis를 사용하면 리스트를 제한된 집합으로 사용하여 최신 N개의 항목만 기억하고 가장 오래된 항목은 LTRIM 명령을 사용하여 모두 버릴 수 있습니다.
LTRIM 명령은 LRANGE와 유사하지만 지정된 범위의 요소를 표시하는 대신 이 범위를 새 리스트의 값으로 설정합니다. 지정된 범위를 벗어난 모든 요소는 제거됩니다.
예를 들어 repairs 리스트 끝에 있는 자전거를 추가할 때, 이전에 처리한 두 개의 자전거는 출고하고 새로 수리가 필요한 가장 최근에 입고된 자전거 3개만 남겨놓고 싶을 때 사용할 수 있습니다.
LTRIM 명령은 Redis에 시작인덱스에서 끝인덱스 까지의 목록 요소만 유지하고 나머지는 모두 버리도록 지시합니다. 이를 통해 매우 간단하지만 유용한 패턴을 만들 수 있습니다.
LPUSH 연산 + LTRIM 연산을 함께 수행하여 새 엘리먼트를 추가하고 한도를 초과하는 엘리먼트를 버리는 것입니다. 그런 다음 음수 인덱스와 함께 LTRIM을 사용하면 가장 최근에 추가된 3개만 유지할 수 있습니다.
가장 최신 3개의 bike만 유지하는 예제는 아래와 같습니다.
127.0.0.1:6379> RPUSH bikes:repairs bike:1 bike:2 bike:3 bike:4 bike:5
(integer) 5
127.0.0.1:6379> LTRIM bikes:repairs -3 -1
OK
127.0.0.1:6379> LRANGE bikes:repairs 0 -1
1) "bike:3"
2) "bike:4"
3) "bike:5"
127.0.0.1:6379>
이를 파이썬으로 작성하면 다음과 같습니다.
import redis
r = redis.Redis(decode_responses=True)
res27 = r.rpush(
"bikes:repairs", "bike:1", "bike:2", "bike:3", "bike:4", "bike:5"
)
print(res27) # >>> 5
res28 = r.ltrim("bikes:repairs", -3, -1)
print(res28) # >>> True
res29 = r.lrange("bikes:repairs", 0, -1)
print(res29) # >>> ['bike:3', 'bike:4', 'bike:5']
성능
리스트의 헤드(head) 또는 끝(tail)에 액세스하는 리스트 연산은 O(1)이므로 효율성이 매우 높습니다. 그러나 리스트 내의 엘리먼트를 조작하는 명령은 일반적으로 O(n)입니다. 이러한 명령의 예로는 LINDEX, LINSERT, LSET 등이 있습니다. 이러한 명령을 실행할 때는 주로 큰 리스트에서 작업할 때 성능저하를 주의해야합니다.
Redis Sets
Redis 집합은 자주 사용하는 프로그래밍 언어의 집합(예: Java 해시셋, Python 집합 등)처럼 작동하는 정렬되지 않은 고유 문자열 모음입니다. Redis 집합을 사용하면 집합 요소 수에 관계없이 O(1) 시간 내에 추가, 제거 및 존재 여부를 테스트할 수 있습니다(즉, 집합 요소 수에 관계없이).
Redis 집합은 고유한 문자열(멤버)의 정렬되지 않은 컬렉션입니다.
- 고유 항목(unique item) 추적(예: 특정 블로그 게시물에 액세스하는 모든 고유 IP 주소 추적).
- 관계를 표현합니다(예: 주어진 역할을 가진 모든 사용자 집합).
- 교차(intersection), 유니온(union), 차이(difference)와 같은 일반적인 집합 연산을 수행합니다.
Redis Set 기본 명령
- SADD는 Set에 새 멤버를 추가합니다.
- SREM은 Set에서 지정된 멤버를 제거합니다.
- SISMEMBER는 Set 멤버가 있는지 문자열을 테스트합니다.
- SINTER는 두 개 이상의 집합이 공통으로 갖는 멤버 Set (즉, 교집합)을 반환합니다.
- SCARD는 Set 의 크기(일명 카디널리티)를 반환합니다.
카디널리티(Cardinality)
카디널리티(Cardinality)는 특정 데이터 집합의 유니크(Unique)한 값의 개수이다.
레디스 Set 예제
SADD 명령은 집합에 새 요소를 추가합니다. 또한 주어진 요소가 이미 존재하는지 테스트하고, 여러 집합 간의 교집합, 합집합 또는 차이를 수행하는 등 집합에 대해 여러 가지 다른 작업을 수행할 수 있습니다.
아래 예제는 기본 사용법을 보여줍니다. SMEMBERS는 실제 해당 Set의 멤버를 모두 보여주며, SISMEMBER는 해당 Set에서 내가 입력한 멤버가 있는지 확인해 줍니다.
레디스 매뉴얼에는 SMISMEMBER 명령이 있는데, 실제 테스트 해보니 동작하지 않는 것 확인하였습니다.
127.0.0.1:6379> SADD bikes:racing:france bike:1 bike:2 bike:3
(integer) 3
127.0.0.1:6379> SMEMBERS bikes:racing:france
1) "bike:2"
2) "bike:1"
3) "bike:3"
127.0.0.1:6379> SISMEMBER bikes:racing:france bike:1
(integer) 1
127.0.0.1:6379> SMISMEMBER bikes:racing:france bike:2 bike:3 bike:4
(error) ERR unknown command `SMISMEMBER`, with args beginning with: `bikes:racing:france`, `bike:2`, `bike:3`, `bike:4`,
두 Set의 차이점을 찾을 수도 있습니다. 예를 들어, 프랑스에서 개최되는 경주에 출전하고 미국 대회에서는 출전하지 않는 자전거를 찾기 위해서는 다음과 같이 SDIFF 명령어를 사용 할 수 있습니다.
127.0.0.1:6379> SADD bikes:racing:usa bike:1 bike:4
(integer) 2
127.0.0.1:6379> SDIFF bikes:racing:france bikes:racing:usa
1) "bike:2"
2) "bike:3"
Redis 명령을 사용하여 쉽게 구현할 수 있는 여러 다른 작업들이 있습니다. 예를 들어 프랑스, 미국 및 기타 레이스에서 경주하는 모든 자전거의 목록이 필요할 수 있습니다. 서로 다른 집합 간의 교집합을 수행하는 SINTER 명령을 사용하여 이를 수행할 수 있습니다. 교차 외에도 유니온, 차이 등을 수행할 수 있습니다. 예를 들어 세 번째 이탈리아에서 개최되는 경주를 추가하여 이러한 명령들이 실제로 작동하는 것을 볼 수 있습니다.
127.0.0.1:6379> SADD bikes:racing:italy bike:1 bike:2 bike:3 bike:4
(integer) 4
127.0.0.1:6379> SINTER bikes:racing:france bikes:racing:usa bikes:racing:italy
1) "bike:1"
127.0.0.1:6379> SUNION bikes:racing:france bikes:racing:usa bikes:racing:italy
1) "bike:2"
2) "bike:1"
3) "bike:4"
4) "bike:3"
127.0.0.1:6379> SDIFF bikes:racing:france bikes:racing:usa bikes:racing:italy
(empty array)
127.0.0.1:6379> SDIFF bikes:racing:france bikes:racing:usa
1) "bike:2"
2) "bike:3"
127.0.0.1:6379> SDIFF bikes:racing:usa bikes:racing:france
1) "bike:4"
파이썬에서는 다음과 같이 코드로 구현할 수 있습니다.
import redis
r = redis.Redis(decode_responses=True)
res1 = r.sadd("bikes:racing:france", "bike:1")
print(res1) # >>> 1
res2 = r.sadd("bikes:racing:france", "bike:1")
print(res2) # >>> 0
res3 = r.sadd("bikes:racing:france", "bike:2", "bike:3")
print(res3) # >>> 2
res4 = r.sadd("bikes:racing:usa", "bike:1", "bike:4")
print(res4) # >>> 2
r.sadd("bikes:racing:france", "bike:1", "bike:2", "bike:3")
r.sadd("bikes:racing:usa", "bike:1", "bike:4")
res5 = r.sismember("bikes:racing:usa", "bike:1")
print(res5) # >>> 1
res6 = r.sismember("bikes:racing:usa", "bike:2")
print(res6) # >>> 1
r.sadd("bikes:racing:france", "bike:1", "bike:2", "bike:3")
r.sadd("bikes:racing:usa", "bike:1", "bike:4")
res7 = r.sinter("bikes:racing:france", "bikes:racing:usa")
print(res7) # >>> {'bike:1'}
r.sadd("bikes:racing:france", "bike:1", "bike:2", "bike:3")
res8 = r.scard("bikes:racing:france")
print(res8) # >>> 3
res9 = r.sadd("bikes:racing:france", "bike:1", "bike:2", "bike:3")
print(res9) # >>> 3
res10 = r.smembers("bikes:racing:france")
print(res10) # >>> {'bike:1', 'bike:2', 'bike:3'}
res11 = r.sismember("bikes:racing:france", "bike:1")
print(res11) # >>> 1
res12 = r.smismember("bikes:racing:france", "bike:2", "bike:3", "bike:4")
print(res12) # >>> [1, 1, 0]
r.sadd("bikes:racing:france", "bike:1", "bike:2", "bike:3")
r.sadd("bikes:racing:usa", "bike:1", "bike:4")
res13 = r.sdiff("bikes:racing:france", "bikes:racing:usa")
print(res13) # >>> {'bike:2', 'bike:3'}
r.sadd("bikes:racing:france", "bike:1", "bike:2", "bike:3")
r.sadd("bikes:racing:usa", "bike:1", "bike:4")
r.sadd("bikes:racing:italy", "bike:1", "bike:2", "bike:3", "bike:4")
res13 = r.sinter(
"bikes:racing:france", "bikes:racing:usa", "bikes:racing:italy"
)
print(res13) # >>> {'bike:1'}
res14 = r.sunion(
"bikes:racing:france", "bikes:racing:usa", "bikes:racing:italy"
)
print(res14) # >>> {'bike:1', 'bike:2', 'bike:3', 'bike:4'}
res15 = r.sdiff("bikes:racing:france", "bikes:racing:usa", "bikes:racing:italy")
print(res15) # >>> set()
res16 = r.sdiff("bikes:racing:usa", "bikes:racing:france")
print(res16) # >>> {'bike:4'}
res17 = r.sdiff("bikes:racing:france", "bikes:racing:usa")
print(res17) # >>> {'bike:2', 'bike:3'}
r.sadd("bikes:racing:france", "bike:1", "bike:2", "bike:3", "bike:4", "bike:5")
res18 = r.srem("bikes:racing:france", "bike:1")
print(res18) # >>> 1
res19 = r.spop("bikes:racing:france")
print(res19) # >>> bike:3
res20 = r.smembers("bikes:racing:france")
print(res20) # >>> {'bike:2', 'bike:4', 'bike:5'}
res21 = r.srandmember("bikes:racing:france")
print(res21) # >>> bike:4
Redis hashes
Redis 해시는 필드 값 쌍의 컬렉션으로 구조화된 레코드 유형입니다. 해시를 사용하여 기본 객체를 표현하고 카운터 그룹을 저장하는 등의 작업을 수행할 수 있습니다.
레디스 해시는 아래와 같이 field와 value의 쌍으로 저장 가능합니다. 물론 제일 처음에 key를 통해 입력할 수 있습니다.
HSET key field value [field value ...]
기본 명령
- HSET은 해시에서 하나 이상의 필드 값을 설정합니다.
- HGET은 지정된 필드의 값을 반환합니다.
- HMGET은 지정된 하나 이상의 필드에서 값을 반환합니다.
- HINCRBY는 지정된 필드의 값을 제공된 정수만큼 증가시킵니다.
Redis 해시 예제
레디스 해시에 대해서 예제를 살펴보겠습니다.
127.0.0.1:6379> HSET bike:1 model Deimos brand Ergonom type 'Enduro bikes' price 4972
(integer) 4
127.0.0.1:6379> HGET bike:1 model
"Deimos"
127.0.0.1:6379> HGET bike:1 price
"4972"
127.0.0.1:6379> HGETALL bike:1
1) "model"
2) "Deimos"
3) "brand"
4) "Ergonom"
5) "type"
6) "Enduro bikes"
7) "price"
8) "4972"
위의 명령들은 레디스의 해시 데이터 구조를 사용하는 예제입니다. 해시는 필드와 값의 맵으로, 각각의 키에 대해 문자열 필드와 문자열 값이 연결되어 있습니다.
- HSET bike:1 model Deimos brand Ergonom type 'Enduro bikes' price 4972: 이 명령은 'bike:1’이라는 키에 대한 여러 필드와 값을 설정합니다. 여기서 ‘model’, ‘brand’, ‘type’, 'price’는 필드이고, ‘Deimos’, ‘Ergonom’, ‘Enduro bikes’, '4972’는 각 필드에 대응하는 값입니다. 이 명령을 실행하면 새로 설정된 필드의 수를 반환합니다. 여기서는 4개의 필드가 설정되었습니다.
- HGET bike:1 model : 이 명령은 ‘bike:1’ 키의 ‘model’ 필드 값을 가져옵니다. 여기서는 "Deimos"를 반환합니다.
- HGET bike:1 price : 이 명령은 ‘bike:1’ 키의 ‘price’ 필드 값을 가져옵니다. 여기서는 "4972"를 반환합니다.
- HGETALL bike:1 : 이 명령은 ‘bike:1’ 키에 대한 모든 필드와 값을 가져옵니다. 반환된 리스트에서 홀수 인덱스는 필드를, 짝수 인덱스는 해당 필드의 값을 나타냅니다. 여기서는 ‘model’, ‘brand’, ‘type’, ‘price’ 필드와 그에 대응하는 ‘Deimos’, ‘Ergonom’, ‘Enduro bikes’, ‘4972’ 값이 반환되었습니다.
Sorted sets
Redis sorted sets은 각 문자열의 연관된 점수에 따라 순서를 유지하는 고유한 문자열의 모음입니다. 자세한 내용은 다음을 참조하세요:
Streams
Redis stream 추가 전용 로그처럼 작동하는 데이터 구조입니다. 스트림은 이벤트가 발생한 순서대로 이벤트를 기록한 다음 처리를 위해 신디케이트하는 데 도움이 됩니다. 자세한 내용은 아래 링크를 참고하세요.
Geospatial indexes
Redis geospatial indexes 지정된 지리적 반경 또는 경계 상자 내에서 위치를 찾는 데 유용합니다. 자세한 아래 링크를 참조하세요.
Bitmaps
Redis bitmaps 은 문자열에 대해 비트 단위 연산을 수행할 수 있는 레디스의 데이터 타입입니다. 자세한 아래 링크를 참조하세요.
Bitfields
Redis bitfields 문자열 값에 여러개의 카운터를 효율적으로 인코딩합니다. 비트필드는 원자적인 가져오기, 설정, 증가 연산을 제공하며 다양한 오버플로 정책을 지원합니다. 자세한 아래 링크를 참조하세요.
HyperLogLog
Redis HyperLogLog 데이터 구조는 대규모 집합의 카디널리티(즉, 요소 수)에 대한 확률적 추정치를 제공합니다. 자세한 아래 링크를 참조하세요.
용어
컬렉션
여러개의 요소로 이뤄진 레디스 데이터 타입을 이야기 합니다.
요소와 엘리먼트
동일한 의미로 특정 컬렉션의 구성요소를 이야기 합니다.
'IT' 카테고리의 다른 글
| TPC-C 벤치마크 tpc.org 공식 5.11 문서 분석 - 테이블 스키마와 구현 규칙 (19) | 2024.03.21 |
|---|---|
| 파이썬을 활용한 NoSQL 몽고디비(MongoDB) 및 Redis TPCC 테스트 소개 및 python 코드 분석 과정 (0) | 2024.03.20 |
| 레디스(Redis) 파이프라이닝(Pipelining)이란? (0) | 2024.03.14 |
| 레디스(Redis) 키 공간(Keyspace)과 사용법 - 키 만료(expiration), 스캔, 변경, 질의 (1) | 2024.03.14 |
| [Python] 파이썬 자료형과 예제 - datatype, example (23) | 2024.03.13 |










